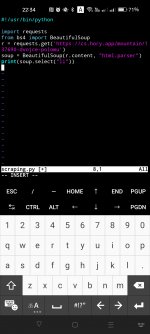
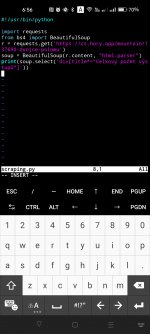
Zdravím. Tady česká podpora. Za prvé to vypadá že používate zastaralou HTTP GET akci místo novější akce pod názvem HTTP požadavek. Ne že by to hodně vadilo, ale doporučuji raději používat tuto. Zadruhé jsem zkoušel HTTP požadavek z MacroDroidu poslat ale nazpátek se mi místo zdrojového kódu požadované stránky vrátilo toto:
HTML:
<h1>Redirect</h1>
<p><a href="https://cs.hory.app/mountain/137690-dvojce-polomu">Please click here to continue</a>.</p>
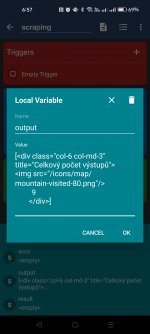
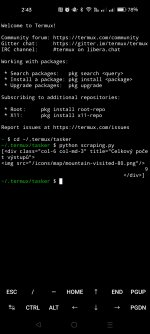
Tak tady se asi zasekneme. Z tohohle počet výstupů jen tak nedostanete. Ten odkaz na který to přesměrovává je mimochodem úplně totožný s tím, který jsem při požadavku použil. Nevím jestli u vás je to to samé a akorát jste si nevšiml, nebo je to jen můj případ. Akce HTTP požadavku má možnost "Pokračovat přes přesměrování" ale její zapnutí mi taky nepomohlo. Vypadá to že stránka Hrobraní má nějakou ochranu proti čtení dat boty, nebo se jen jedná o nějakou nešikovnost? Aktuálně netuším jak se přes tohle dostat pokud to vůbec jde.
EN:
Hello. This is Czech support. First of all, it looks like you are using the deprecated HTTP GET action instead of the newer action called HTTP Request. Not that it matters much, but I recommend using this one instead. Second, I tried to send an HTTP request from MacroDroid but this is what came back instead of the source code of the requested page:
HTML:
<h1>Redirect</h1>
<p><a href="https://cs.hory.app/mountain/137690-dvojce-polomu">Please click here to continue</a>.</p>
I guess this is where we get stuck. You're not gonna get what you wanted from this. The link it redirects to, by the way, is exactly the same as the one I used to make the request. I don't know if it's the same for you and you just didn't notice, or if it's just me. The HTTP request action has a "Continue via redirect" option but turning it on didn't help me either. It looks like the Horobraní page has some protection against bots reading the data, or is it just some kind of clumsiness? I currently have no idea how to get past this if at all possible.