Don't take it too seriously. No one's angry at you. Next time I will be careful with using angry emoticon reaction.
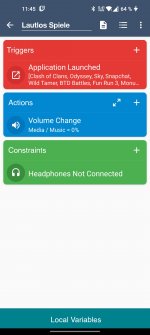
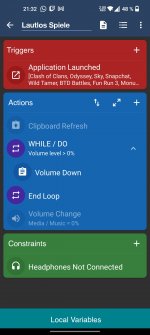
Althought I understand your good intentions to make the macro work for more devices (even thought that's something OP doesn't need), I think you didn't read the original post carefully. In your screenshot you are trying to get clipboard content on Android 10+ and 9-, however we are trying to change the audio volume from foreground instead of background (not save clipboard content into a variable nor anything related to clipboard content) and this issue is problem of different manufacturers rather than different Android SDK versions.
Hyrum’s Law
If you are maintaining a project that is used by other engineers, the most important lesson about “it works” versus “it is maintainable” is what we’ve come to call Hyrum’s Law: With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody. In our experience, this axiom is a dominant factor in any discussion of changing software over time. It is conceptually akin to entropy: discussions of change and maintenance over time must be aware of Hyrum’s Law8 just as discussions of efficiency or thermodynamics must be mindful of entropy. Just because entropy never decreases doesn’t mean we shouldn’t try to be efficient. Just because Hyrum’s Law will apply when maintaining software doesn’t mean we can’t plan for it or try to better understand it. We can mitigate it, but we know that it can never be eradicated. Hyrum’s Law represents the practical knowledge that—even with the best of intentions, the best engineers, and solid practices for code review—we cannot assume perfect adherence to published contracts or best practices. As an API owner, you will gain some flexibility and freedom by being clear about interface promises, but in practice, the complexity and difficulty of a given change also depends on how useful a user finds some observable behavior of your API. If users cannot depend on such things, your API will be easy to change. Given enough time and enough users, even the most innocuous change will break something;9 your analysis of the value of that change must incorporate the difficulty in investigating, identifying, and resolving those breakages.
8 To his credit, Hyrum tried really hard to humbly call this “The Law of Implicit Dependencies,” but “Hyrum’s Law” is the shorthand that most people at Google have settled on. 9 See “Workflow,” an xkcd comic. 8 | Chapter 1: What Is Software Engineering?
Example:
Hash Ordering Consider the example of hash iteration ordering. If we insert five elements into a hash-based set, in what order do we get them out?
>>> for i in {"apple", "banana", "carrot", "durian", "eggplant"}:
print(i)
durian carrot apple eggplant banana
Most programmers know that hash tables are non-obviously ordered. Few know the specifics of whether the particular hash table they are using is intending to provide that particular ordering forever. This might seem unremarkable, but over the past decade or two, the computing industry’s experience using such types has evolved: • Hash flooding10 attacks provide an increased incentive for nondeterministic hash iteration. • Potential efficiency gains from research into improved hash algorithms or hash containers require changes to hash iteration order. • Per Hyrum’s Law, programmers will write programs that depend on the order in which a hash table is traversed, if they have the ability to do so. As a result, if you ask any expert “Can I assume a particular output sequence for my hash container?” that expert will presumably say “No.” By and large that is correct, but perhaps simplistic. A more nuanced answer is, “If your code is short-lived, with no changes to your hardware, language runtime, or choice of data structure, such an assumption is fine. If you don’t know how long your code will live, or you cannot promise that nothing you depend upon will ever change, such an assumption is incorrect.” Moreover, even if your own implementation does not depend on hash container order, it might be used by other code that implicitly creates such a dependency. For example, if your library serializes values into a Remote Procedure Call (RPC) response, the RPC caller might wind up depending on the order of those values. This is a very basic example of the difference between “it works” and “it is correct.” For a short-lived program, depending on the iteration order of your containers will not cause any technical problems. For a software engineering project, on the other hand, such reliance on a defined order is a risk—given enough time, something will.
10 A type of Denial-of-Service (DoS) attack in which an untrusted user knows the structure of a hash table and the hash function and provides data in such a way as to degrade the algorithmic performance of operations on the table.
Time and Change
Make it valuable to change that iteration order. That value can manifest in a number of ways, be it efficiency, security, or merely future-proofing the data structure to allow for future changes. When that value becomes clear, you will need to weigh the tradeoffs between that value and the pain of breaking your developers or customers. Some languages specifically randomize hash ordering between library versions or even between execution of the same program in an attempt to prevent dependencies. But even this still allows for some Hyrum’s Law surprises: there is code that uses hash iteration ordering as an inefficient random-number generator. Removing such randomness now would break those users. Just as entropy increases in every thermodynamic system, Hyrum’s Law applies to every observable behavior. Thinking over the differences between code written with a “works now” and a “works indefinitely” mentality, we can extract some clear relationships. Looking at code as an artifact with a (highly) variable lifetime requirement, we can begin to categorize programming styles: code that depends on brittle and unpublished features of its dependencies is likely to be described as “hacky” or “clever,” whereas code that follows best practices and has planned for the future is more likely to be described as “clean” and “maintainable.” Both have their purposes, but which one you select depends crucially on the expected life span of the code in question. We’ve taken to saying, “It’s programming if ‘clever’ is a compliment, but it’s software engineering if ‘clever’ is an accusation.”
From "Software Engineering at Google" Chapter 1